

Now that we have so many programming languages, it is hard to choose which one is good for us(keeping in mind the outcome that we expect). In this series of blog, I’ll cover few programming languages and their architecture, so that you know what the languages is offering and what are the tradeoffs.
In this blog, we’ll cover nodeJS.
With no further due, Let’s jump In:
Origin Of NodeJS
Node.js is an open-source, cross-platform JavaScript runtime environment that allows developers to execute JavaScript code outside of a web browser. It was created in 2009 by Ryan Dahl and has since become one of the most popular JavaScript runtime environments, with a large and active community.
Dahl noticed that the majority of web applications were heavily reliant on blocking I/O operations, which meant that the server had to wait for a response from an external resource before it could continue processing the next request. This led to poor performance and scalability, as the server could only handle a limited number of requests at a time.
To address these limitations, Dahl created Node.js, which features an event-driven, non-blocking I/O architecture. This means that it uses an event loop to handle asynchronous I/O operations and can handle a large number of concurrent connections with high throughput and low latency.
How does it works?
Node.js is a JavaScript runtime environment that allows developers to execute JavaScript code outside of a web browser. It is built on top of the V8 JavaScript engine, which was developed by Google for use in the Chrome browser.
V8 is responsible for compiling and executing JavaScript code, and it also provides a low-level API for interacting with the operating system.
v8 directly compiled the javascript code into machine code making it super fast.
Node.js extends the capabilities of V8 by providing a number of additional modules and features. One of the key features of NodeJs is its event-driven, non-blocking I/O architecture.
It uses an event loop to handle asynchronous I/O operations and can handle a large number of concurrent connections with high throughput and low latency.
Node.js also has a number of built-in modules, such as the HTTP module which allows developers to create HTTP servers and clients, and the FS module which provides an API for interacting with the file system. This means that developers can create a full-featured web server with just a few lines of code.
LIBUV
libuv is a multi-platform C library that provides an abstraction layer for various I/O operations, such as file system operations, networking, and timers. It is used by Node.js to provide a consistent and portable API for performing I/O operations on different platforms.
libuv was created by Joyent, the company that originally developed Node.js, as a way to provide a common set of I/O functions for Node.js across different operating systems.
It provides an event loop and a non-blocking I/O model that is similar to the one used by Node.js, but at a lower level.
The event loop in libuv is responsible for managing the flow of I/O operations. It is implemented using a combination of operating system specific APIs and a set of custom implementations.
The event loop works by polling for I/O events and then calling the appropriate callback functions when an event occurs. This allows libuv to handle multiple I/O operations simultaneously, without blocking the execution of other tasks.
libuv also provides a number of other features, such as:
Asynchronous file system operations: libuv provides an API for performing file system operations, such as reading and writing files, asynchronously. This allows Node.js to perform file system operations without blocking the event loop.
Networking: libuv provides an API for performing network operations, such as creating TCP and UDP sockets, asynchronously. This allows Node.js to perform network operations without blocking the event loop.
Thread pool: libuv provides a thread pool that can be used to perform blocking operations, such as file system operations, in the background. This allows Node.js to perform blocking operations without blocking the event loop.
Timers: libuv provides an API for creating and managing timers, which allows NodeJs to schedule tasks to be executed at a later time.
Let’s try to understand with an example:
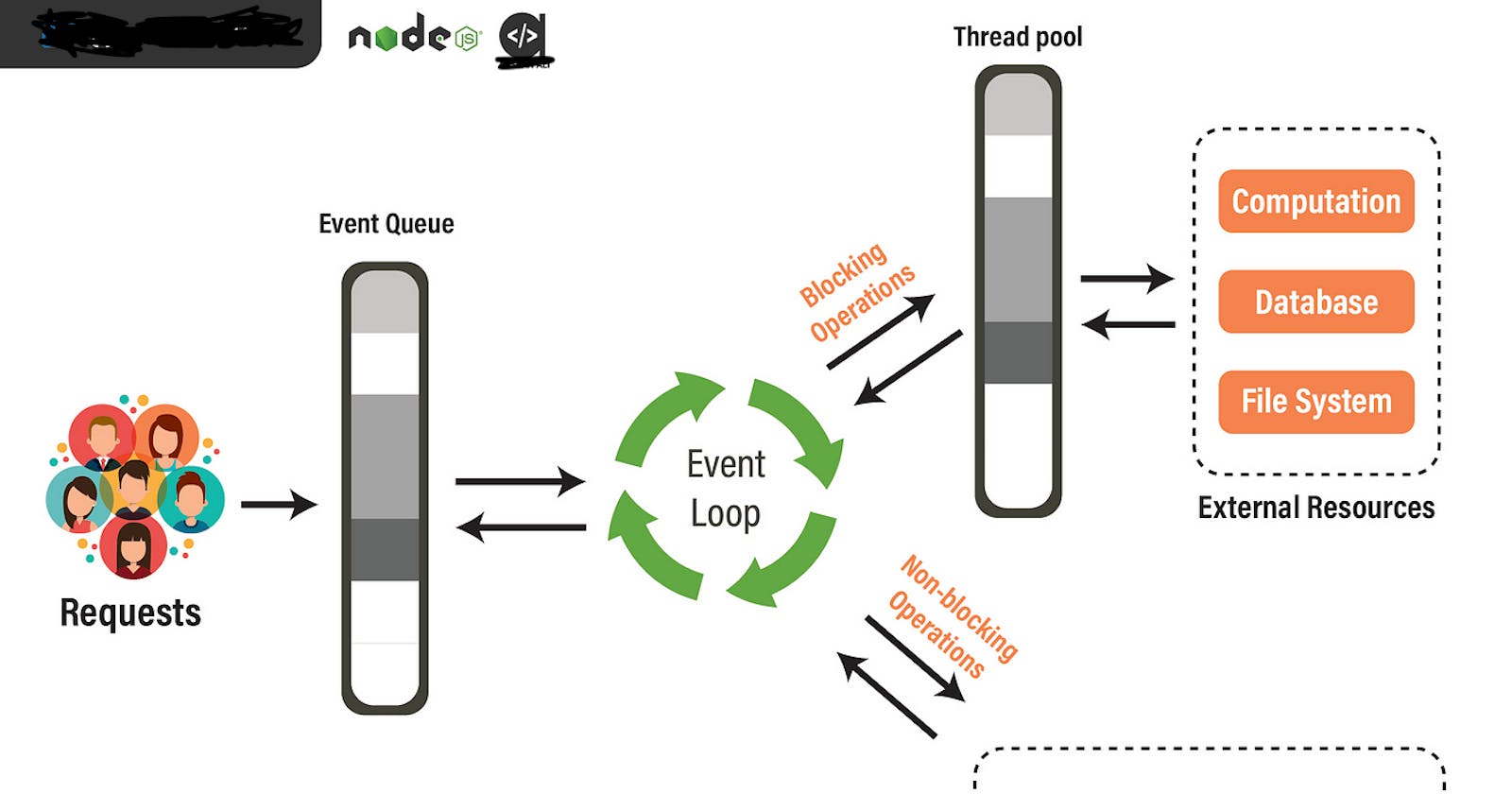
Let say we have a web app where clients are requesting certain data from our server and we are taking that from our database.
When a request comes in , it is registered in the event Queue, Being a Queue, is follows FIFO(first in , first out).
The event loop checks if the event queue is empty or not, if not , it takes the request and pass it to the thread pool.
Thread poll is developed in c++, it can make use multi threading feature and spin up multiple threads . Thread pool will have the database request in asynchronous way and request data from the db.
when thread poll completed the tasks, request is passed back to event loop through callback.
Event loop will pass the event back to the client as response.
Let’s try to understand with another example:
In Node.js, creating a web server is as simple as creating an HTTP server using the built-in HTTP module, and listening for incoming requests
const http = require('http');
const server = http.createServer((req, res) => {
res.writeHead(200, { 'Content-Type': 'text/plain' });
res.end('Hello, World!');
});
server.listen(3000, () => {
console.log('Server is listening on port 3000');
});
In this example, we first import the built-in HTTP module using the require function. We then use the createServer method to create an HTTP server and pass it a callback function that will be called for every incoming request. In this callback function, we write a simple response to the client, specifying the HTTP status code and the content type.
Finally, we call the listen method to start the server and specify the port number on which we want to listen for incoming requests.
When a client, such as a web browser, makes a request to our server, the event loop in Node.js will register the request and pass it to the callback function that we defined. The callback function will then process the request and send a response back to the client.
While the callback function is executing, the event loop is free to handle other incoming requests.
This means that our server can handle multiple requests simultaneously, which is one of the key advantages of the non-blocking I/O architecture in Node.js.
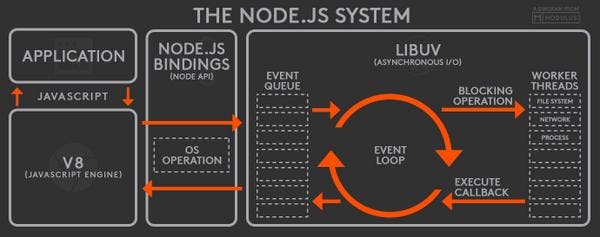
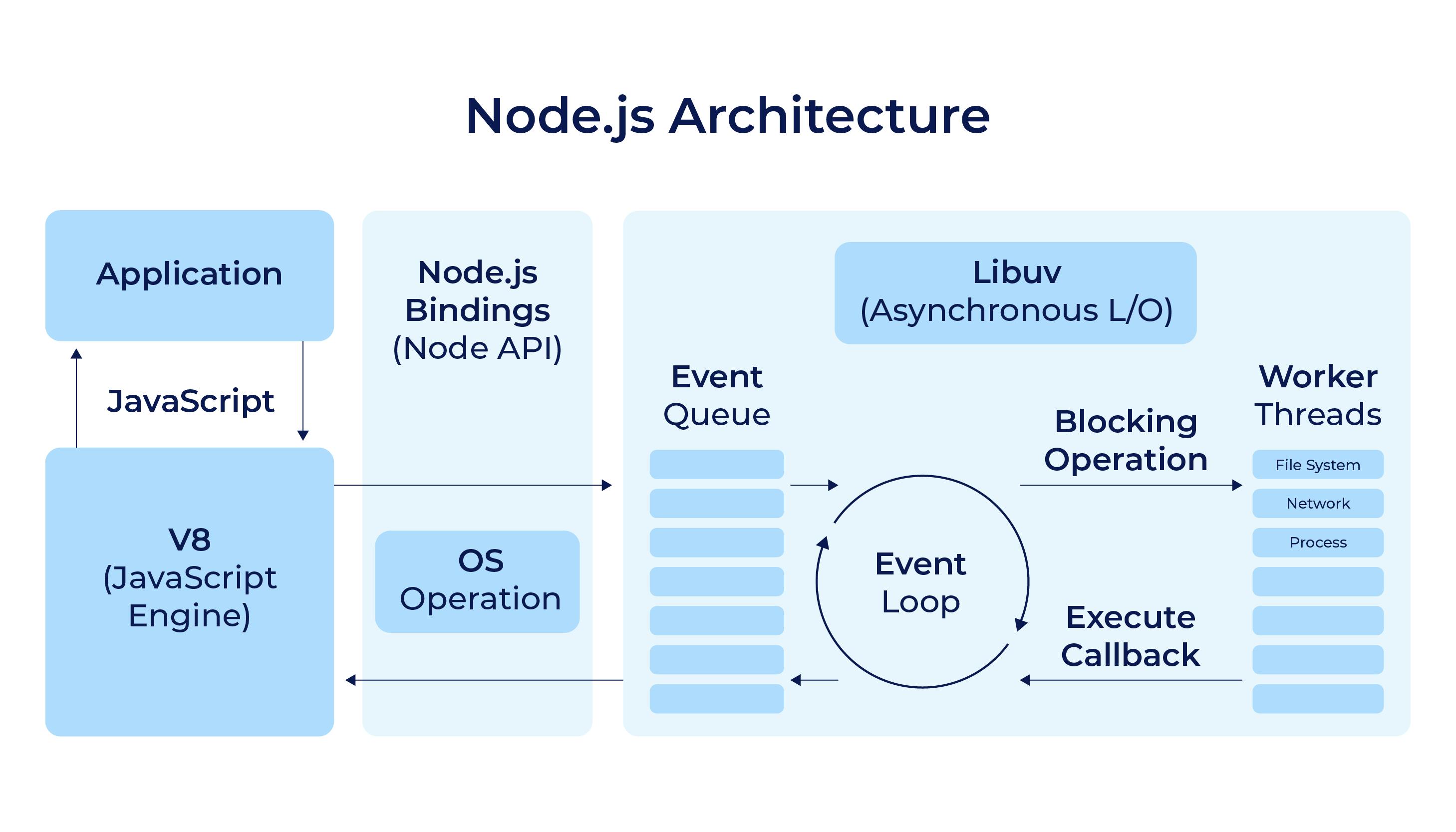
Code written in your application gets compiled by V8. The code communicates with low-level Node.js components via bindings. All the events written in your code are registered with Node.js. Once events are triggered, they are enqueued in the event queue according to the order that they are triggered.
As long as there still are remaining events in the event queue, the event loop keeps picking them up, calling their callback functions, and sending them off to worker threads for processing. Once a callback function is executed, its callback is once again send to the event queue, waiting to be picked up by the event loop again.
What are the use cases of this language?
NodeJs is a versatile technology that can be used for a wide range of use cases. Some of the most common use cases for NodeJs include:
Web development: Node.js is well-suited for building web applications and RESTful APIs, thanks to its event-driven, non-blocking I/O architecture and its large ecosystem of web frameworks such as Express.js, Koa.js, Meteor.js, Nest.js and Hapi.js.
Real-time applications: Node.js is often used for building real-time applications such as chat systems, online gaming, and IoT applications. Its ability to handle a large number of concurrent connections and its support for WebSockets make it well-suited for these types of applications.
Command line tools: Node.js can be used to create command line tools and utilities that can be run from the terminal. This is thanks to its built-in modules for interacting with the file system and its ability to run JavaScript code outside of a web browser.
Desktop applications: Node.js can be used to create desktop applications using frameworks like Electron. This allows developers to build cross-platform desktop applications with JavaScript and web technologies.
Microservices: Node.js is often used to build microservices architecture, it is lightweight and fast, it can handle a lot of concurrent connections, and it has a large ecosystem of libraries to build, test and deploy microservices.
Automation: Node.js can be used to automate repetitive and complex tasks such as web scraping, data processing, and testing.
Artificial Intelligence: Node.js can be used to build AI-based applications, it can be used with libraries like Tensorflow.js, which allows developers to run machine learning models in the browser and on the server-side.
Serverless: NodeJs is one of the most popular languages for building serverless functions, it is lightweight, fast and has a large ecosystem of libraries, this makes it easy to build, test and deploy functions on serverless platforms like AWS Lambda, Azure Functions, and Google Cloud Functions
What are the tradeoffs?
Node.js is a powerful and popular technology, but it also comes with some trade-offs that developers should be aware of. Some of the main trade-offs with Node.js include:
Single-threaded nature: Node.js runs on a single thread, which means that it can only handle one request at a time. This can lead to performance bottlenecks in certain situations, especially when dealing with CPU-bound tasks or high-concurrency scenarios. To overcome this limitation, Node.js uses a technique called “clustering” which allows multiple instances of Node.js process to share the load and handle more requests.
Memory management: Node.js uses a garbage collector to automatically manage memory, which can cause pauses in execution known as “garbage collection pauses.” These pauses can affect the performance of real-time applications, and developers must pay attention to memory usage and write efficient code to avoid these pauses.
Callback Hell: Node.js uses callbacks extensively to handle asynchronous operations, which can lead to callback hell, where the code becomes hard to read and manage due to deeply nested callbacks. This can be avoided by using Promises, Async/Await, and other libraries that simplify asynchronous code.
JavaScript limitations: JavaScript, the language that Node.js is built on, has some limitations compared to other languages such as C or Java. For example, JavaScript is not as fast as other languages, and it does not have built-in support for multi-threading. This can be a limitation for certain types of performance-critical applications.
Stability of packages: Node.js has a large ecosystem of packages, but not all of them are stable and well-maintained. This means that developers may encounter compatibility issues or bugs when using certain packages, which can lead to unexpected behavior or downtime. To mitigate this risk, developers should use packages that are well-maintained and have a large number of users and contributors.
If you like this blog and interested in reading more content like this do check out my other blogs & follow for email updates.